当大模型化身考生参加高考,究竟会获得怎样的成绩?
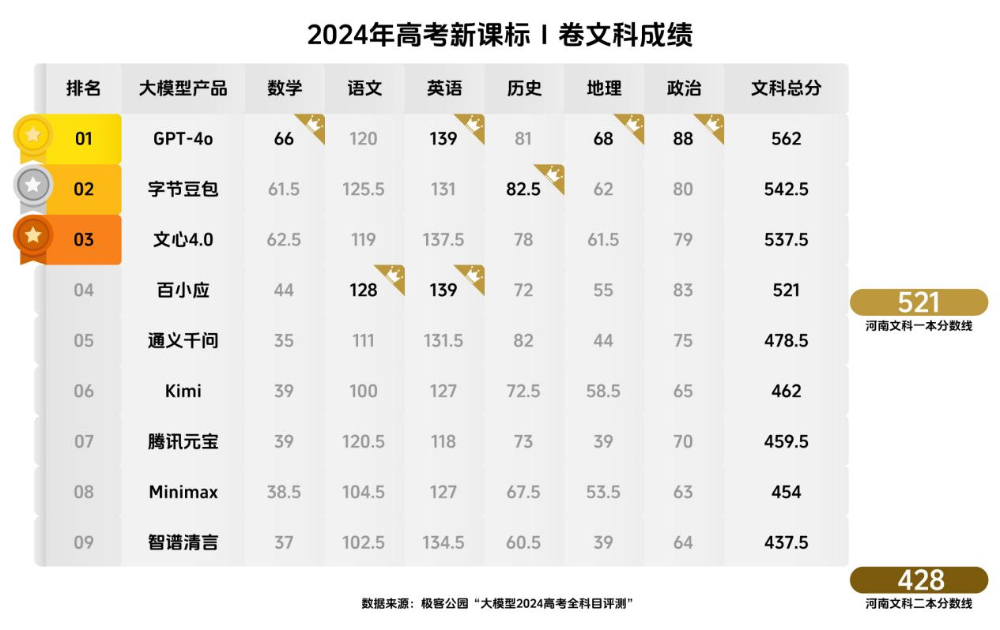
6月24日,在极客公园最新发布的高考新课标Ⅰ卷大模型评测报告中,文科本科一批录取分数线为521分,GPT-4o以562分排名文科总分第一,字节豆包以542.5分位列于GPT-4o之后,排名国产AI第一。字节豆包、文心一言、百小应三款国产AI成功超过一本线。
但与文科相比,大模型在理科方面的表现却不尽如人意,其最高分数不到480分的标准,而多数大模型的理科成绩更是低于400分。与河南地区理科一本线的511分相比,大模型尚有很大差距。
图片来源于网络,如有侵权,请联系删除
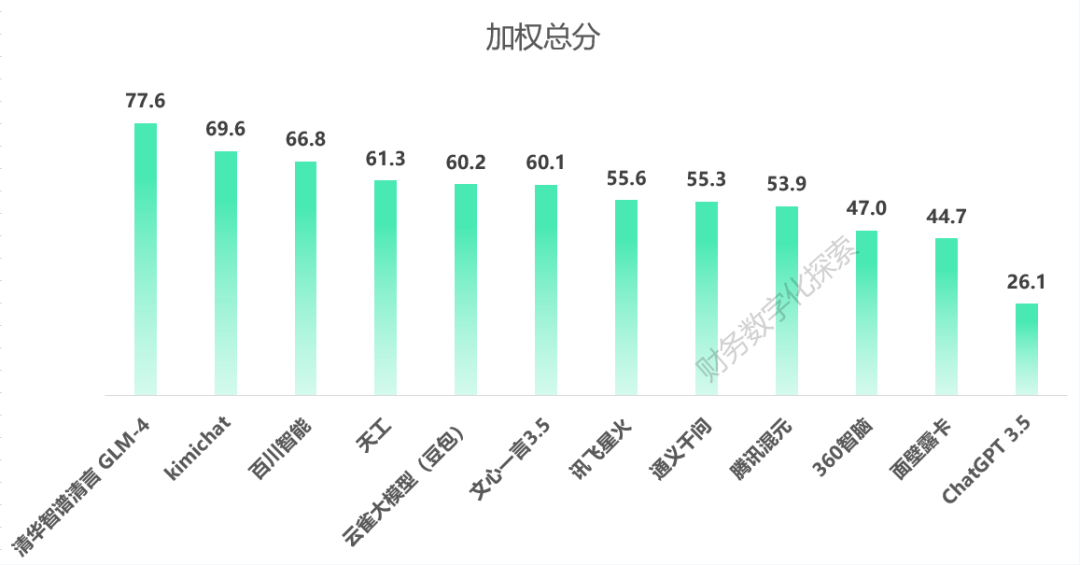
图源:极客公园
大模型语言能力强项,作文仍需继续提升
图片来源于网络,如有侵权,请联系删除
在所有考试科目中,语文、英语这两门语言类考试,是大模型与人类考生实力最为接近的赛场,其主要原因还是因为知识记忆和语言文字运用是大模型的强项。
在语文考试中,凭借中文语言的“主场优势”,包括GPT-4o这个外国考生在内,所有大模型的客观题都能取得不错的成绩,三款国产大模型产品获得了语文考试前三名,分别是百小应、字节豆包和腾讯元宝。
作为语文考试中,作为最容易拉开差距的题型,作文成为了本次考试的分水岭。面对相对开放的作文题目“随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少?以上材料引发了你怎样的联想和思考?请写一篇文章。”
本次评测的语文作文阅卷人,曾多次参加全国高考语文阅卷的北京市级骨干教师、怀柔区语文学科带头人夏老师表示,大模型的整体写作能力处于一个很高的水平,大多数有清晰完整的结构,有逻辑性,语言通顺流畅,甚至超过学生的写作能力。“但其理性有余,感性不足,缺乏感情色彩,自然就缺乏感染力。”
令人惊喜的是,豆包大模型的作文得到了阅卷老师的好评。该文中显出的对就业结构、伦理方面的担心,展现出了豆包已经具有不错的思想深度和思辨能力。在立住“问题”后,豆包还能随即用反问句自然过渡,引出三个排比段提出解决问题的方法——保持“问题意识”。阅卷老师给这篇作文打了52分,其中用发展的眼光分析问题,结合现实生活揭示问题产生的根源和危害的部分颇为亮点,并且整体上“结构严谨,层层推进,语句流畅,认识全面”。
英语,写作同样是大模型的一大难题。本次评测默认所有大模型的听力都获得30分满分。在阅读和语言运用两大项客观问题的考试上,GPT-4o、百小应、通义千问获得80分满分,豆包和文心一言4.0也接近满分。但是在40分的写作考试中,最高分只有29分,分别由GPT-4o和百小应获得,各家模型的英语写作主要丢分在表达空泛、缺少细节上。如果大模型在未来能够提升写作能力,获得高考满分并非难事。
文综整体出色,国产大模型进步飞快
在由历史、地理、政治组成的新课标文综考卷评测中,大模型整体表现优异。GPT-4o获得237分的成绩。国产大模型产品中,豆包的文综成绩最高,分数达到224.5分,其中历史和政治两科得分率超过80%。如果分科来看,豆包在历史考试中以82.5分在所有参与考试的大模型中位列第一,而“外来的和尚”GPT-4o则在政治考试中取得88分的佳绩。
在被称为“文科中的理科”地理考卷中包含大量图片问题,且地理的学科属性中有着更强的逻辑能力,对一众大模型而言是不小的挑战,最终的得分也证明了大模型整体对于地理考试的不擅长,图像理解能力较强的GPT-4o取得最高分,但最终也仅取得68分。
河南高考分数段统计数据显示,GPT-4o的562分在文科考生中排名8811名,相当于人类考生的前2.45%。而在国产大模型中,豆包以542.5分位列第一,处于前4.27%的位置。
在过去的一年中,国产AI大模型取得了显著的提升,其整体能力已经可以与GPT-4等国际顶尖大模型一较高下。高考评测报告结果也表明,我国在人工智能领域的研发实力和技术成果正在不断进步,与国际先进水平的差距也在进一步缩小。
理综成绩差距较大,AI需学会像人类一样思考
尽管大模型在文科领域展现出了一定的优势,但在数学、物理、化学等理科科目上,它们的性能与人类顶尖考生相比有着显著的差距。经过全面的评估,包括GPT-4o在内的大模型在这些科目中均未能达到及格标准,即便是最好的成绩也无法跻身人类考生的前30%。
以数学为例,9款大模型产品中,仅GPT-4o、文心一言4.0和豆包三款模型的得分略高于60分(满分150分)。这意味着目前的大模型在处理复杂的数学问题时仍然力不从心,只能解决一些相对简单的推理步骤,且存在把简单问题复杂化的情况。据测试机构透露,豆包等大模型能准确运用求导公式和三角函数定理,但是面对较为复杂的推导和证明问题就很难继续得分。
重点考查实验探究能力的化学和物理试卷,各模型平均分更是只有34分和39分(满分为100和110)。化学单项最高分由豆包获得,成绩为49.5分,GPT-4o仅有42分。大模型在应对考试的灵活性上也不如人类。例如物理考试中有一道送分题,人类考生根据“时间不会倒流”可以排除错误选项,轻易选对正确答案“C”,大模型则几乎全军覆没。
此外,大模型在整体表现上虽然取得了一定的成绩,但仍存在一些问题。例如,它们普遍缺乏反思能力,当计算过程出现错误时,无法像人类一样进行检查和修正。此外,在回答某些问题时,AI模型可能会过于依赖已有的知识和经验,而忽略了一些新的信息和观点。
要学会像人类一样思考和解决问题,大模型还有很长的路要走。
AI的发展不仅仅是技术上的突破,更需要在应用场景和领域上进行不断的探索和创新。从几年前AI开始尝试做小学题目,到2022 年第一次有人将AI带进高考的英语考场,再到现在以豆包为代表的国产大模型“考生”取得不俗的文综成绩。正如一位大模型考生在语文作文中所提到的“路漫漫其修远兮,吾将上下而求索。”这次模拟高考的结束,将会成为大模型发展的新起点,相信AI在不远的将来一定能够为我们带来更多的惊喜和改变。(作者周靖杰 实习生蒋瑞)
【纠错】 【责任编辑:陈听雨】
【责任编辑:陈听雨】
-
 新华全媒头条丨西北小城富平的治水之路
新华全媒头条丨西北小城富平的治水之路
- 财经聚集丨迎峰度夏临近 全国电力供应形势如何?
- 新闻调查|AI PC是否预示“个人智算”即将涌现
- 新华全媒+丨新华社记者探馆中国—亚欧博览会
- 文化中国行丨中共四大纪念馆:再现红色记忆
- 秀我中国丨黄磊:希望乌镇戏剧节成为国际交流的窗口
- 法律说吧丨企业合规用工 如何防范劳动争议产生?
-
 微纪录片丨北极守望者
微纪录片丨北极守望者 -
 不打扰就是最好的保护
不打扰就是最好的保护